Self Attention
The three big papers that led to the original form of self-attention were:
- Neural Machine Translation by Jointly Learning to Align and Translate (2014)
- Effective Approaches to Attention-based Neural Machine Translation (2015)
- Attention is all you need (2017)
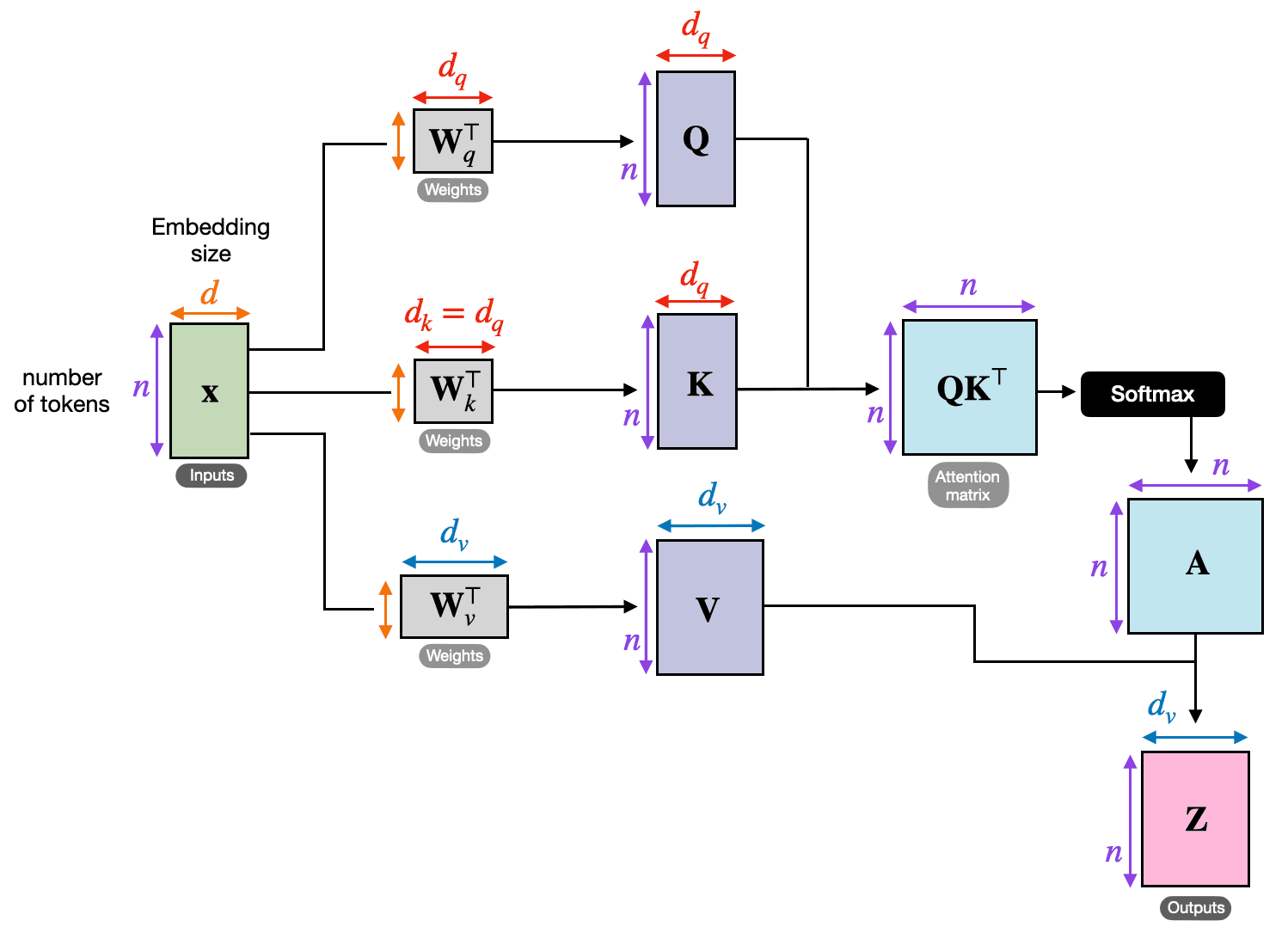
Standard self-attention, as described in Attention is all you need, is expressed like so:
In code, this looks like:
def self_attention(X, W_q, W_k, W_v):
"""
X: (seq_len, d_model) - input embeddings
W_q, W_k: (d_k, d_model) - query/key projection weights
W_v: (d_v, d_model) - value projection weights
"""
# Project to Q, K, V
Q = X @ W_q.T # (seq_len, d_k)
K = X @ W_k.T # (seq_len, d_k)
V = X @ W_v.T # (seq_len, d_v)
# Scaled dot-product attention
d_k = K.shape[1]
scores = Q @ K.T / (d_k**0.5) # (seq_len, seq_len)
attn_weights = F.softmax(scores, dim=-1)
# Weighted sum of values
output = attn_weights @ V # (seq_len, d_v)
return output, attn_weightsAnd visually it looks like this (from here):
From first principles
How do we go from a standard linear layer, which transforms each token independently, to a mechanism that lets a token build a representation from the rest of the sequence?
We'll use a toy example around the word bank, which can mean different things in different contexts:
river bank mudmoney bank loan
Why a linear layer is not enough
Suppose x is a sequence of token embeddings with shape (n_tokens, d_in).
A standard linear layer applies the same transformation to each row:
y = x @ WThat can change the features of each token, but it does not let tokens communicate. If the input row for bank is the same in two different sentences, then the output row for bank will also be the same.